
A KCS Perspective
Experience is often a good and reliable source of knowledge. Having solved a problem before gives us a head start when we are faced with the same problem or a similar one. Likewise, relying on an institution’s collective problem-solving experience and familiarity with issues is a good place to start when building a knowledge base (KB). This idea is one of the cornerstones of Knowledge Centered Support (KCS) methodology of knowledge management, which has been proven to be quite effective in establishing an effective KB. The central tenet of KCS is to allow support agents create knowledge as they are handling a case, making problem solving a starting point of knowledge generation. Many organizations have adopted this approach over the years and practiced it successfully to bring their agents’ experience into their KB.
Knowledge and How it Helps
A well-constructed KB cuts through the noise of the discovery steps by focusing on the essence of a problem and directing the reader towards the common denominators of a diagnostic process. It is designed to capture knowledge, and allows for authors to come back and update the content to add or modify any information regarding an issue as needed. KB does not particularly care about the history of specific cases where that issue was encountered. Knowledge stems from our ability to filter out the unnecessary details and reach the parts that are intrinsic to an issue. It is possible in the KCS methodology to focus on the relevant parts of an issue while delivering support.
The main goals of KCS are to:
- Create useful content to solve problems/issues
- Update information based on demand and usage
- Create KB by capturing, structuring, and reusing an organization’s collective experience
- Learn, collaborate, share and improve
For this blog post, we would like to focus on a very specific situation, i.e., why existing support cases, service requests, or tickets are not a good resource to build KBs on, and why they do not provide effective access to an organization’s collective experience and knowledge.
What a Service Ticket Does
Service or support tickets are created when the user of a product or service has an issue or a question and needs an organization’s help in resolving it. It can be external, such as one raised by a customer, or internal, such as one raised by an employee. The ticket helps a customer support agent to track this interaction. All steps towards the resolution of the ticket, whether it is a problem being solved, question answered, or requests filed with engineers, field technicians, or developers or the support organization’s response in general is entered into that ticket for reference.
Relevant information a ticket may hold includes the name of the person who reported a problem, the date the problem was reported, a description of the problem, and different actions taken to help resolve the problem.
A common example of how service tickets are raised is:
- A customer calls, chats, completes a form, or sends an email about a problem/issue.
- A customer service agent receives the issue and verifies the problem that needs to be resolved. The agent tries to get as much relevant information about the problem as possible.
- The agent inputs all the relevant data regarding the problem in a system. The system is updated with new and relevant data while the agent works on the problem. The agent notes the step(s) taken to try to resolve the problem.
- If the problem is resolved, the ticket is marked as resolved or completed. If unresolved, the ticket will be marked as incomplete, open or pending. An open ticket may be reopened if more information is available to help resolve the issue.
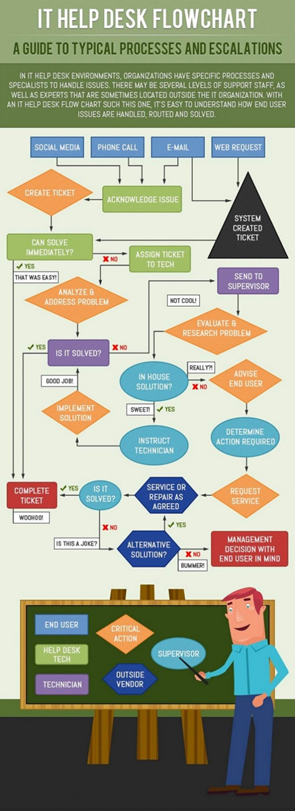
The Limited Nature of Service Tickets
Service tickets typically come with a finite lifespan. Once a case is closed, there is no reason for support center agents to update old tickets with new information. As such, any salient information obtained after the resolution of the issue, such as any clarification, additional diagnostic methods, or what was learned from another similar case, will naturally be left out of the ticket.
As a result, an agent trying to extract knowledge out of the ticket does not have access to all that is known about the issue in question, or the collective knowledge that the agents have accumulated in dealing with the problem. Instead, it documents only the history of a specific instantiation of that issue: the specifics of a particular case, what it took to close it. That is directly related to the purpose that tickets serve: they are case records, not a record of the insights gained from handling similar cases.
The Support Demand Curve (A demand rises, peaks and recedes.)
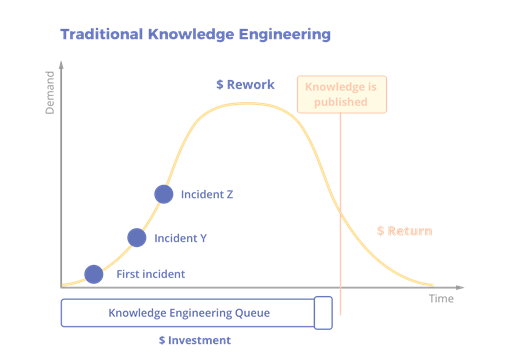
To understand why old tickets are not as useful a source of knowledge as one would assume, it is important to understand their context, function, and structure: the purpose of service tickets is to track the actions taken in the resolution of a particular case, as opposed to capturing knowledge or providing clarity to the issues, which are the qualities that matter most building a KB.
A good KB article needs to be able to tell the reader how to recognize the problem, how to diagnose it and provide a root cause analysis where applicable, its potential symptoms, and the steps needed to resolve it. In other words, it needs to be structured in a way that captures the essence of what is known, rather than the specifics of what was done in a specific situation.
Is it a Good Idea to Mine Tickets?
Looking into an old case that has been resolved and tracing the steps of a previous agent who encountered a similar issue can be highly instructive and valuable, but this is often not the most efficient way to get to that solution. Sometimes it is a challenge to identify an old case as being the same as what one is working on at a given time. Issues have a way of manifesting themselves in different ways depending on the exact configuration of any given situation. Just from a practical point of view an agent searching the KB may not be entering the problem into the search box in a way that is comparable to how the other instance appeared to the previous agent. There is a likelihood that because of the specifics of each case, search is not able to connect the dots between the two cases.
Once the issue underlying a case appears similar enough to what some other agent encountered before, being able to identify this as the same underlying issue may require a different diagnostic path than what was indicated in the existing ticket. The tests may be following different logical paths even though they are arriving at the same end point. For example, the issue may be cause by:
Moreover, mixing private and public cloud services, or Cloud to Cloud Connectivity, businesses become more flexible and have access to more options with how they use data. Likewise, CRM needs to evolve to include Always on Connectivity, or real-time connectivity, which allows for access to information any time and from anywhere on any device.
- An Operating System upgrade
- A missing library file or a conflict with another application
- Some network issue
These are all potential causes identified in each case. Without understanding the issue first, or without any unifying and methodically laid out knowledge around an issue, it would:
- Be harder to get a sense of why the previous method of diagnosis may not apply to this case
- Cause the return of inaccurate results in one instance but accurate ones in another
- Be much harder for an agent to know how to identify or confirm the issue correctly
Call centers are not laboratories where problems can be analyzed with all the superfluous information and incidental correlations stripped out. When one attacks a problem in an environment where the premium is on closing a case and not necessarily providing a thorough investigation, due to understandable economic incentives involved, the record obtained from an issue resolution is likely not to capture the essence of the problem and its root cause, with all the dots connected. It is likely to contain quite a bit unhelpful bits that need to be sifted through. More often than not, all the relevant information will be in the ticket, but with other things that do not necessarily contribute to the resolution.
The KCS Process: Gathering, Structuring and Recycling
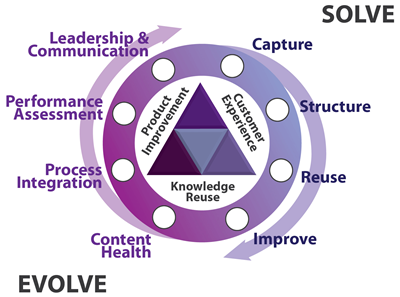
Knowledge stems from our ability to filter out the noise and reach the parts that are intrinsic to an issue. This is where the way the case record is structured comes into play. It is possible in the KCS methodology to focus on the relevant parts of an issue while delivering support, but in those instances, the article that is being created in real time is specifically designed as a KB article that forces the agent to focus on the relevant parts that can be constructed into a KB article, and not a support case.
One thing that we need to bear in mind is that the fact that a case is closed does not necessarily indicate that the case has been resolved or that we know what exactly resolved the case. A case on its own is a singular entity and the ticket associated with it is the record of that particular case. The confirmation that a solution provided in a single case is the resolution of the issue does not come from the case itself. It stems from the fact that subsequent cases that present the same issue are also closed using the same steps and issues closed in this manner are not reopened.
In other words, the key in capturing the collective knowledge of an institution is not only to know what the knowledge is, but to know that it is collective and collaborative. A KB article handles this by:
- Simply being there, updated by agents handling subsequent cases
- Confirming the effectiveness of the solution
- Providing refinements on the solution presented in the article by modifying and adjusting it through time, and strengthening the article in the process
This is the basic insight of the KCS methodology and it is achieved by not relying on case records but on KB articles, created for a much different reason and maintained by the contributions of the entire group.
Our Take
Service tickets may be helpful in specific situations and may provide a stop gap measure until a proper knowledge base is built, but they cannot be expected to be able to provide a solid foundation. What makes them an unhelpful source is not that they are not written well, but that they are intended to capture something else.
KCS responds to this question by encouraging organizations to tap into the knowledge that support agents already have and use on a daily basis when they are resolving issues. Organizing this knowledge into the construction of a KB, with articles specifically designed to capture knowledge, which are regularly edited, updated, and enhanced during the course of their work as they learn more about the nature of the problem they are dealing with. This is a decidedly slower process towards building a healthy bulk of knowledge, as opposed to tapping into the existing reservoir of service tickets. As such, organizations may understandably opt for a hybrid approach in the beginning that make some use of the SRs until KB article creation reaches a satisfactory level. However, this should be considered a temporary measure. Success stories in KCS strongly suggest that initial patience by management and trust placed on the support agents provides high rewards down the line.
Do you practice KCS in your Organization? Do you think you are using knowledge base in the best possible way?